Our Publications
2026
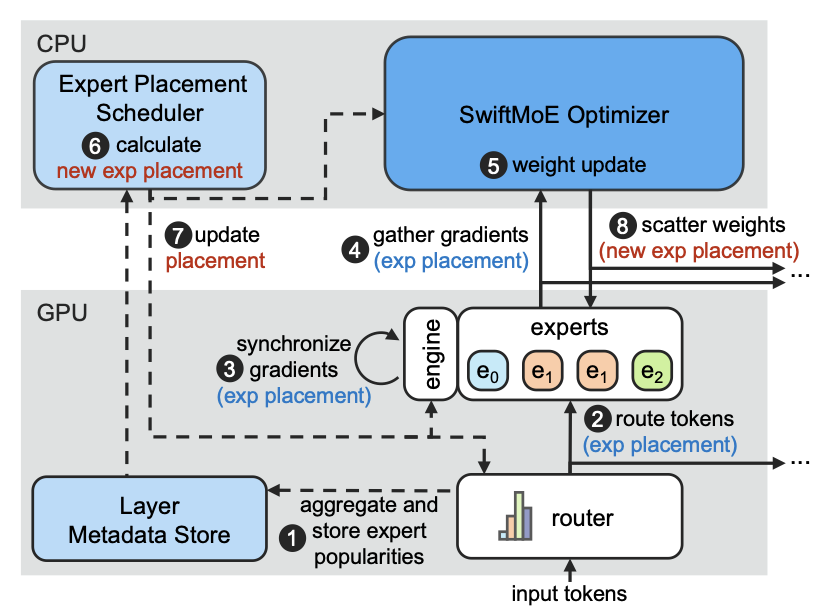
SYMI: Efficient Mixture-of-Experts Training via Model and Optimizer State Decoupling
USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2026
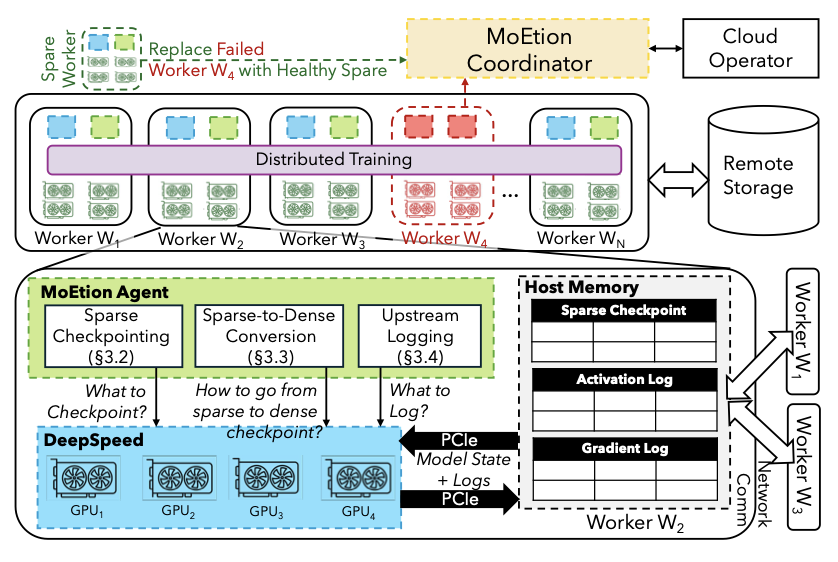
Sparse Checkpointing for Fast and Reliable MoE Training
USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2026
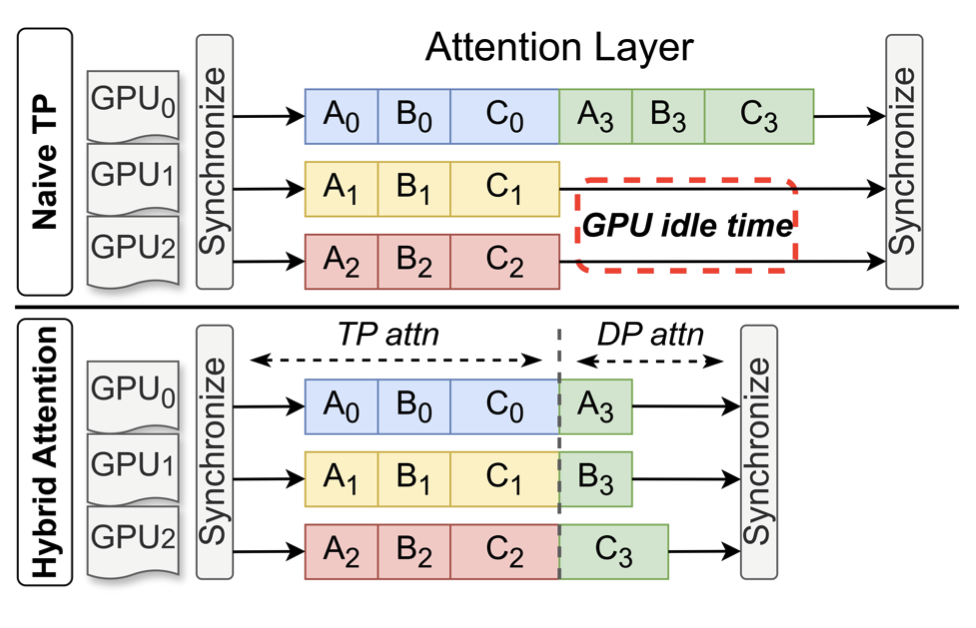
FailSafe: High-performance Resilient Serving
Conference on Machine Learning and Systems (MLSys), 2026
2025
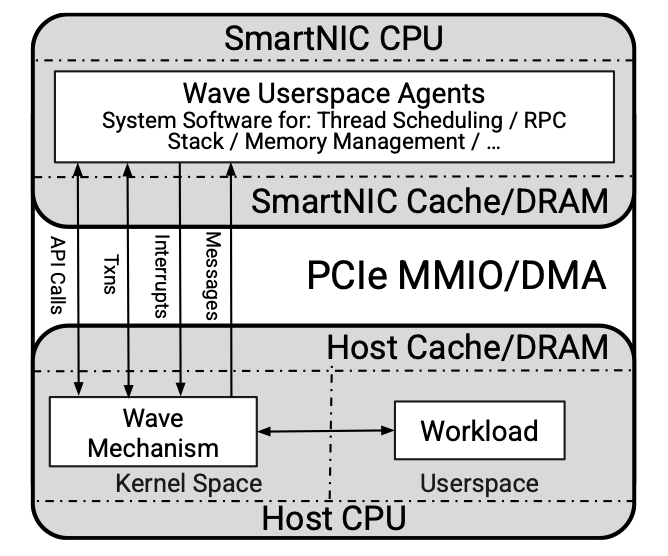
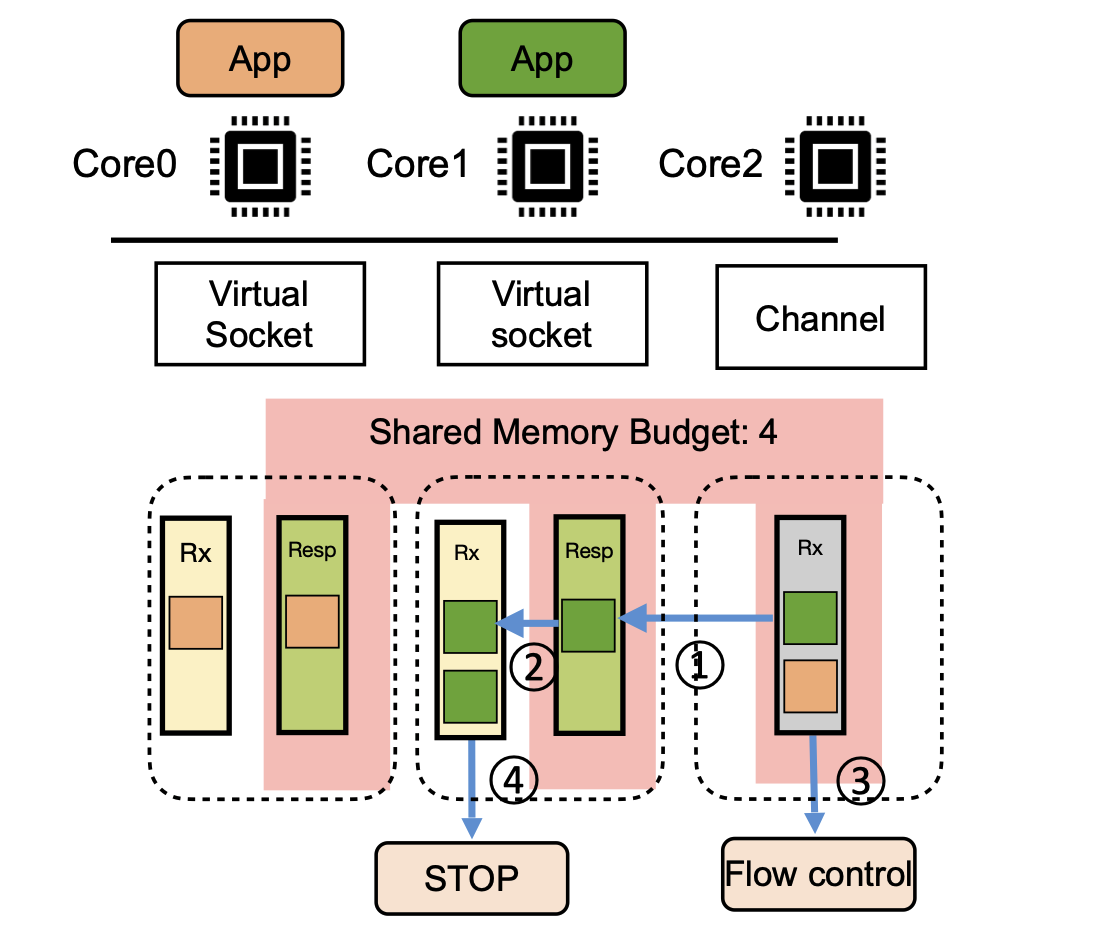
Wave: A Split OS Architecture for Application Engines
ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2025
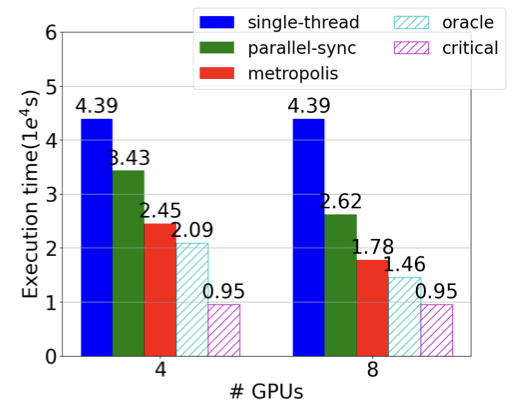
AI Metropolis: Scaling Large Language Model-based Multi-Agent Simulation with Out-of-order Execution
Conference on Machine Learning and Systems (MLSys), 2025

Teaching Cloud Infrastructure and Scalable Application Deployment in an Undergraduate Computer Science Program
ACM Technical Symposium on Computer Science Education (SIGCSETS), 2025
2024

Sglang: Efficient execution of structured language model programs
Conference on Neural Information Processing Systems (NeurIPS), 2024
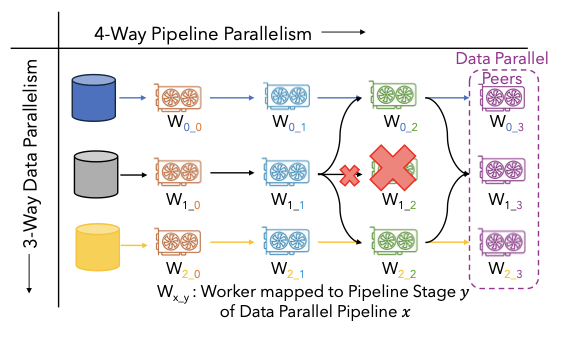
ReCycle: Resilient Training of Large DNNs using Pipeline Adaptation
ACM SIGOPS Symposium on Operating Systems Principles (SOSP), 2024
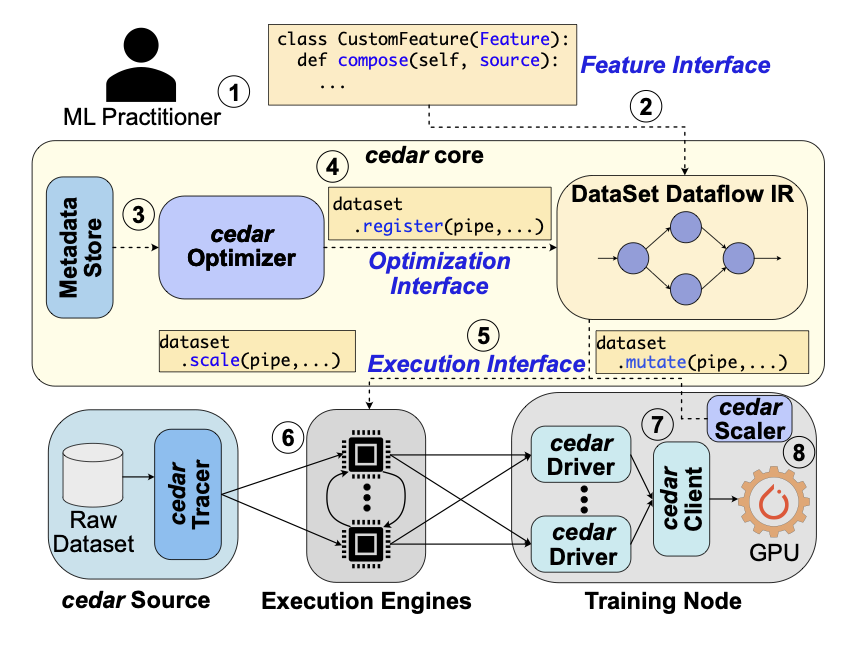
cedar: Optimized and Unified Machine Learning Input Data Pipelines
The International Journal on Very Large Data Bases (VLDB), 2024
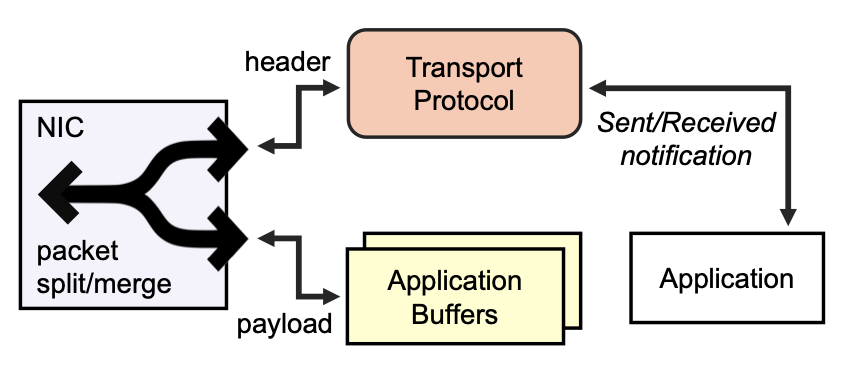
High-throughput and Flexible Host Networking for Accelerated Computing
USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2024
2023
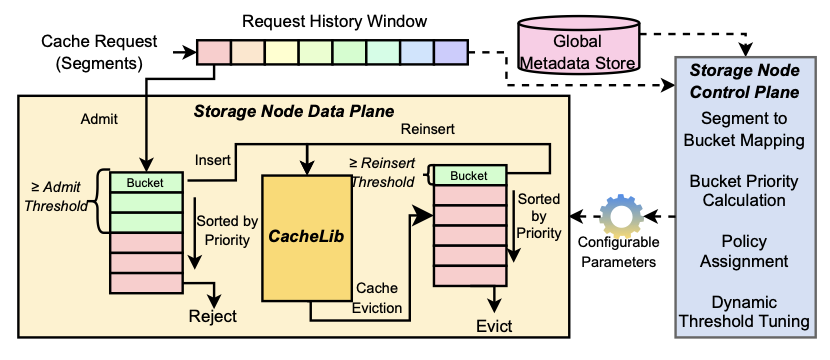
Tectonic-Shift: A Composite Storage Fabric for Large-Scale ML Training
USENIX Annual Technical Conference (USENIX ATC), 2023
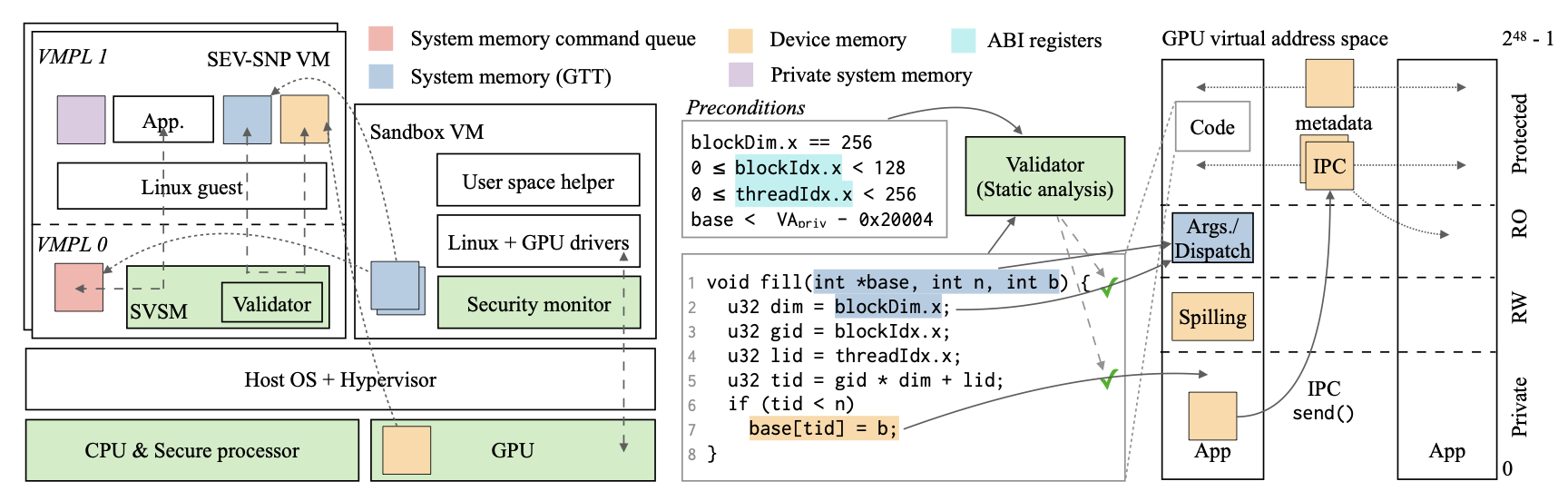
Honeycomb: Secure and Efficient GPU Executions via Static Validation
USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2023
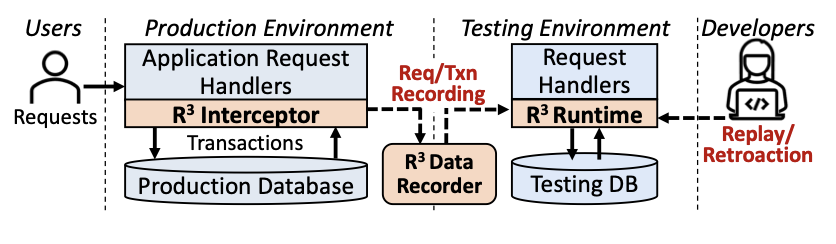
R3: Record-Replay-Retroaction for Database-Backed Applications
The International Journal on Very Large Data Bases (VLDB), 2023
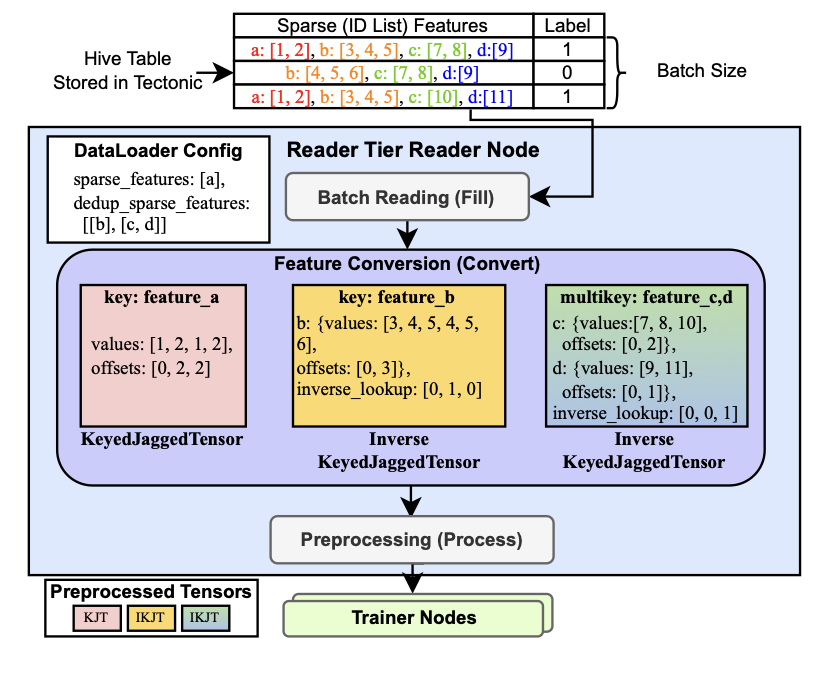
RecD: Deduplication for end-to-end deep learning recommendation model training infrastructure
Conference on Machine Learning and Systems (MLSys), 2023
2022
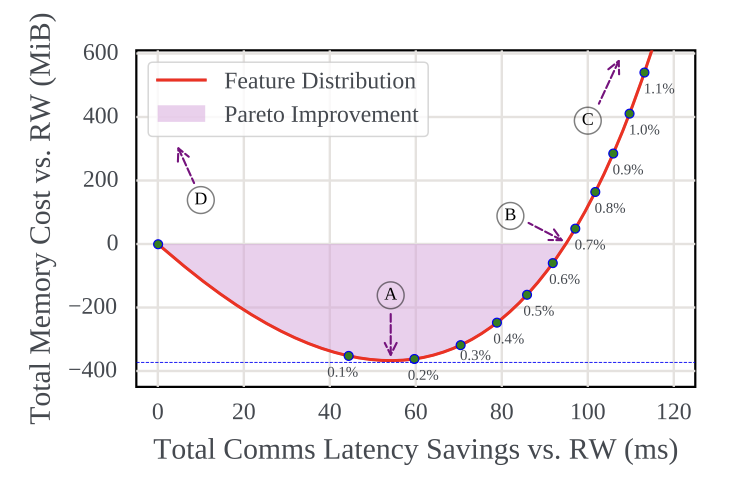
Optimizing video analytics with declarative model relationships
The International Journal on Very Large Data Bases (VLDB), 2022
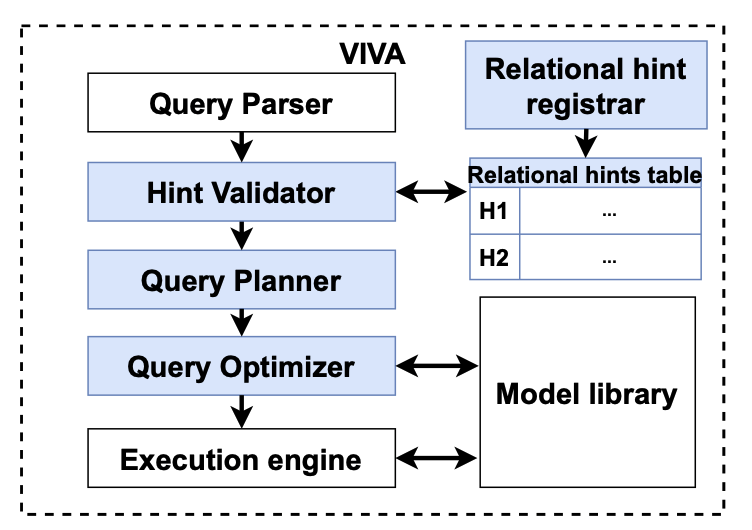
Hermod: principled and practical scheduling for serverless functions
ACM Symposium on Cloud Computing (SoCC), 2022
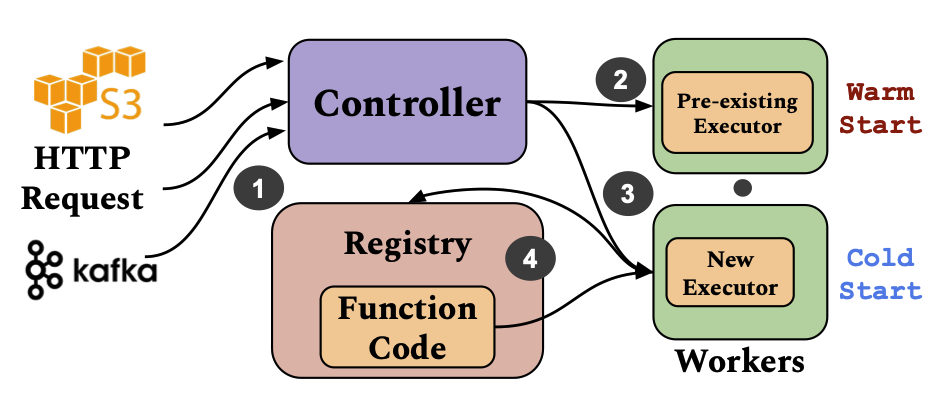
Towards μs tail latency and terabit ethernet: disaggregating the host network stack
ACM Special Interest Group on Data Communication (SIGCOMM), 2022
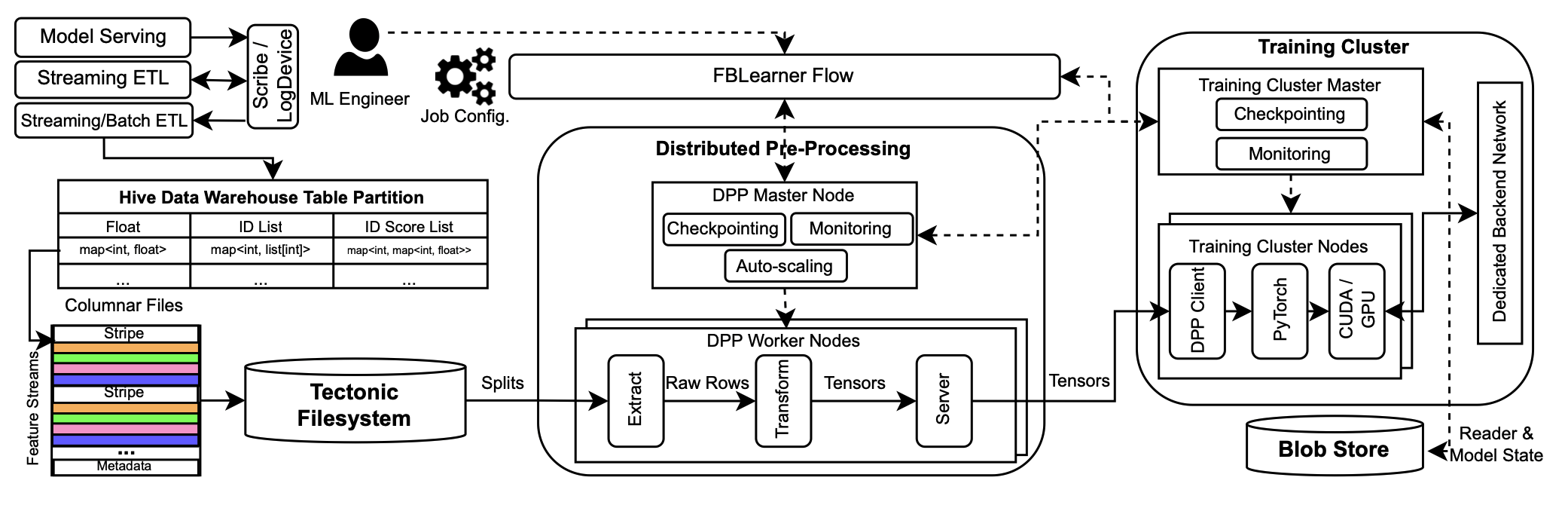
Understanding data storage and ingestion for large-scale deep recommendation model training: Industrial product
International Symposium on Computer Architecture (ISCA), 2022

SOL: Safe on-node learning in cloud platforms
ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2022
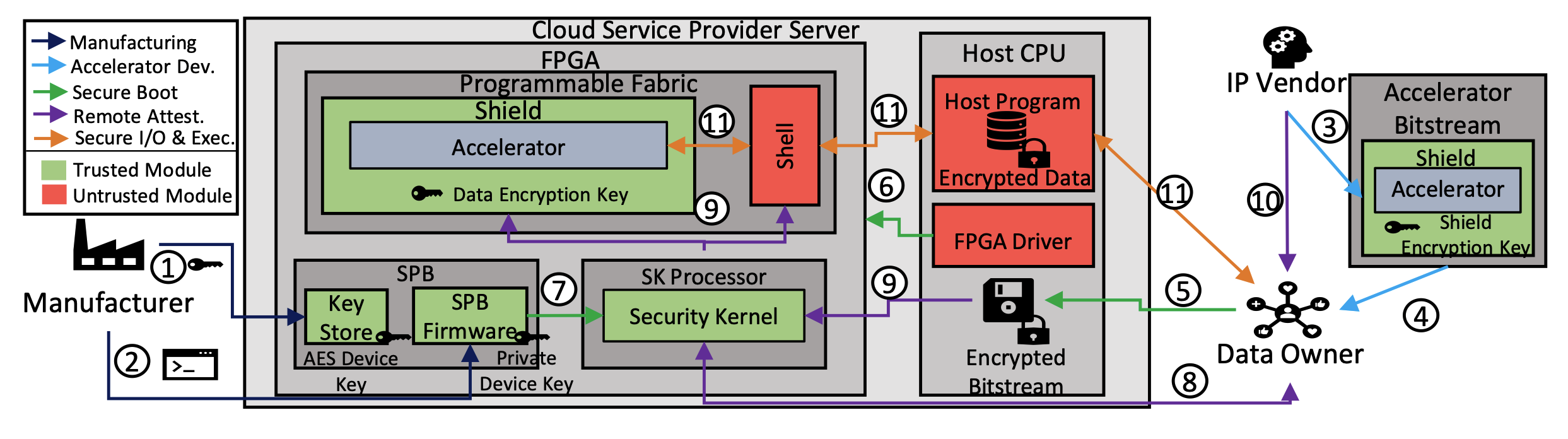
ShEF: Shielded enclaves for cloud fpgas
ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2022
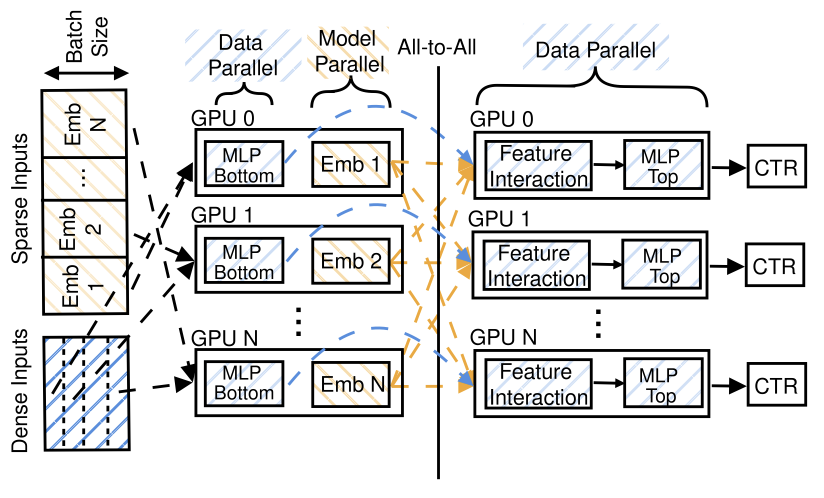
RecShard: statistical feature-based memory optimization for industry-scale neural recommendation
ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2022
2021
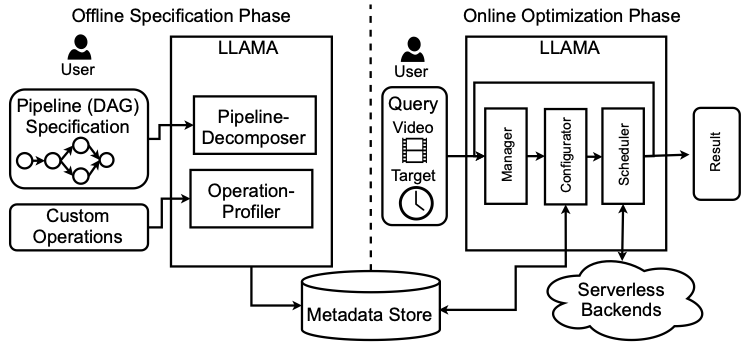
Llama: A heterogeneous & serverless framework for auto-tuning video analytics pipelines
ACM Symposium on Cloud Computing (SoCC), 2021
Faa$t: A Transparent Auto-Scaling Cache for Serverless Applications
ACM Symposium on Cloud Computing (SoCC), 2021
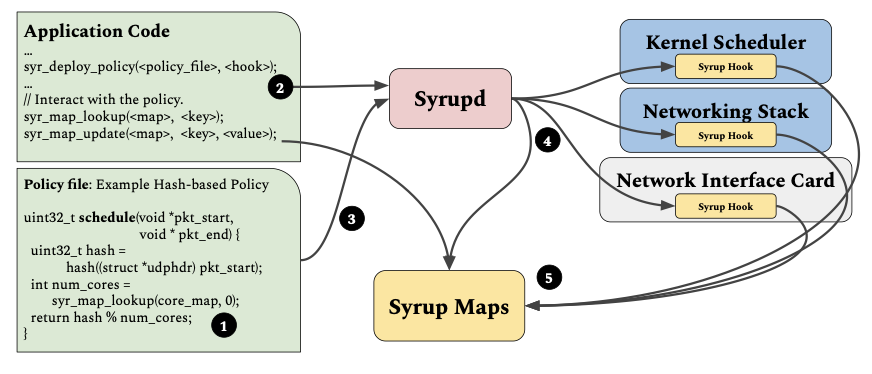
Syrup: User-defined scheduling across the stack
ACM SIGOPS Symposium on Operating Systems Principles (SOSP), 2021
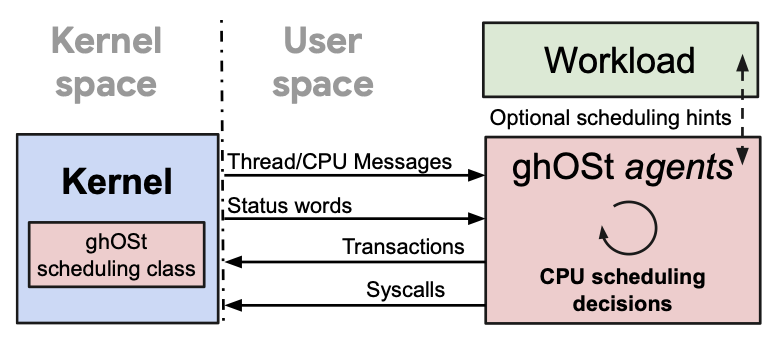
ghOSt: Fast & Flexible User-Space Delegation of Linux Scheduling
ACM SIGOPS Symposium on Operating Systems Principles (SOSP), 2021
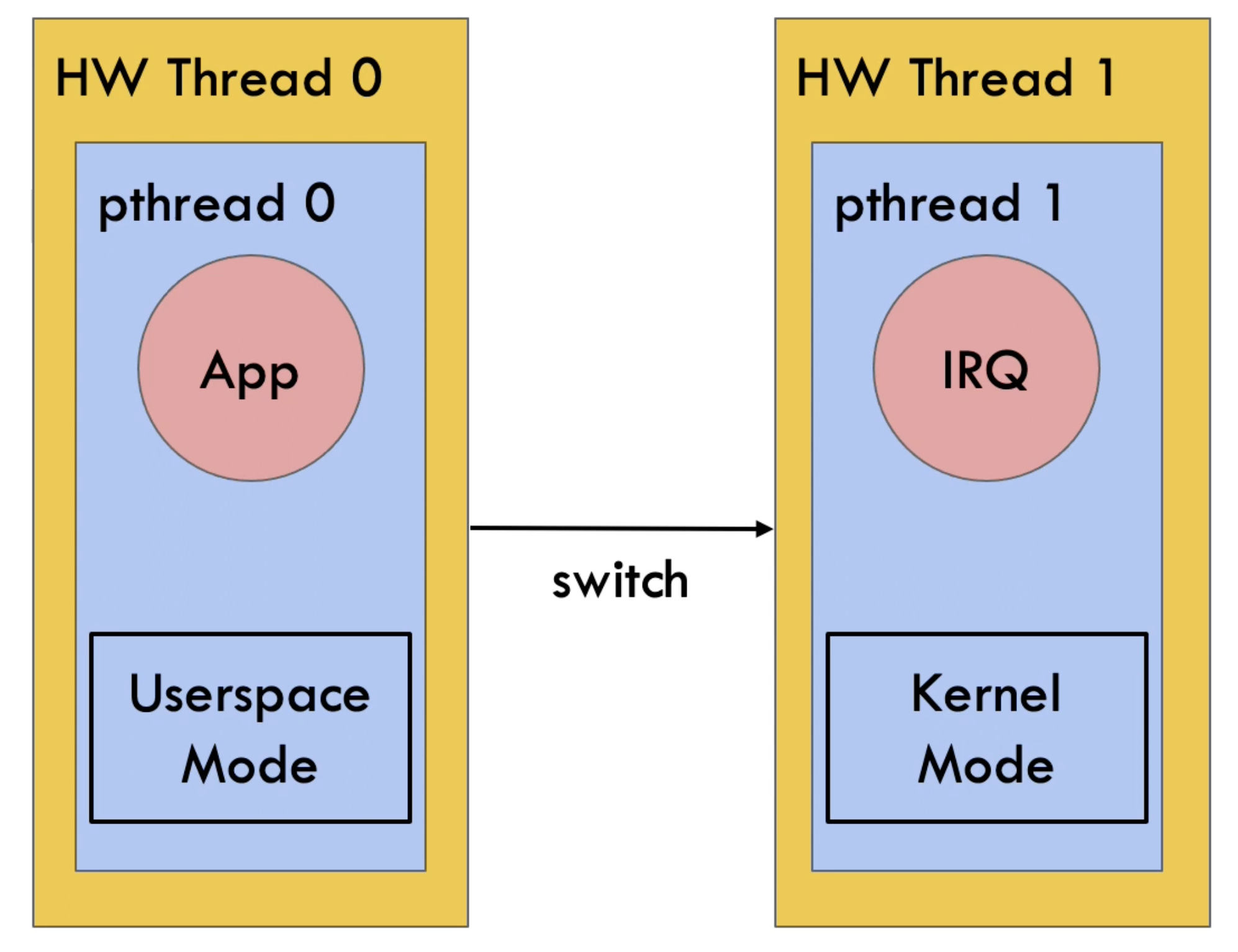
A case against (most) context switches
USENIX Workshop on Hot Topics in Operating Systems (HotOS), 2021
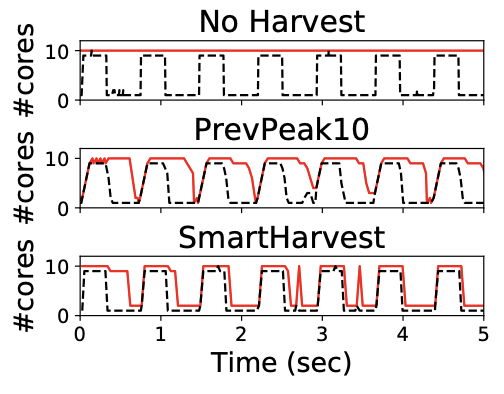
Smartharvest: Harvesting idle cpus safely and efficiently in the cloud
European Conference on Computer Systems (EuroSys), 2021
Interference-aware scheduling for inference serving
European Conference on Machine Learning Systems (EuroMLSys), 2021
RAMBO: Resource allocation for microservices using Bayesian optimization
IEEE Computer Architecture Letters, 2021
2020
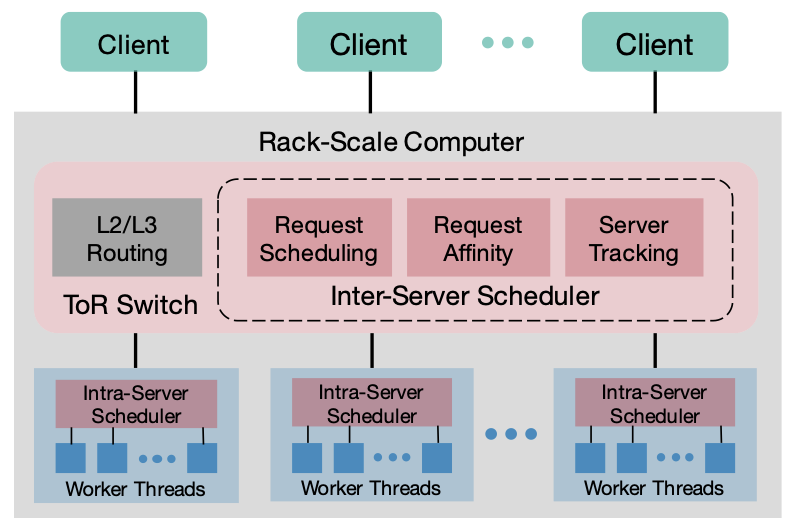
RackSched: A microsecond-scale scheduler for rack-scale computers
USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2020
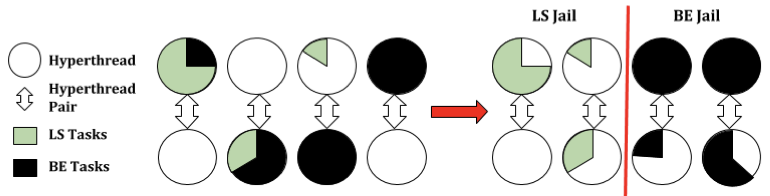
Leveraging application classes to save power in highly-utilized data centers
ACM Symposium on Cloud Computing (SoCC), 2020
A polystore based database operating system (DBOS)
International Conference on Very Large Data Bases (VLDB) Workshop, 2020
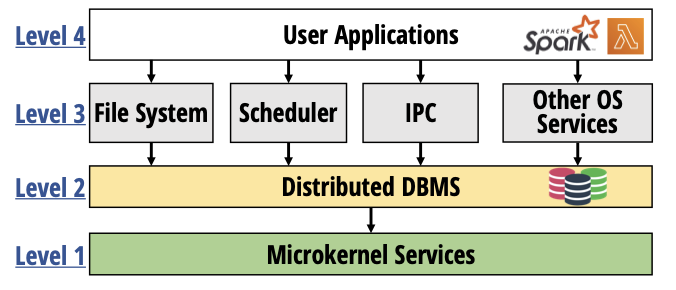
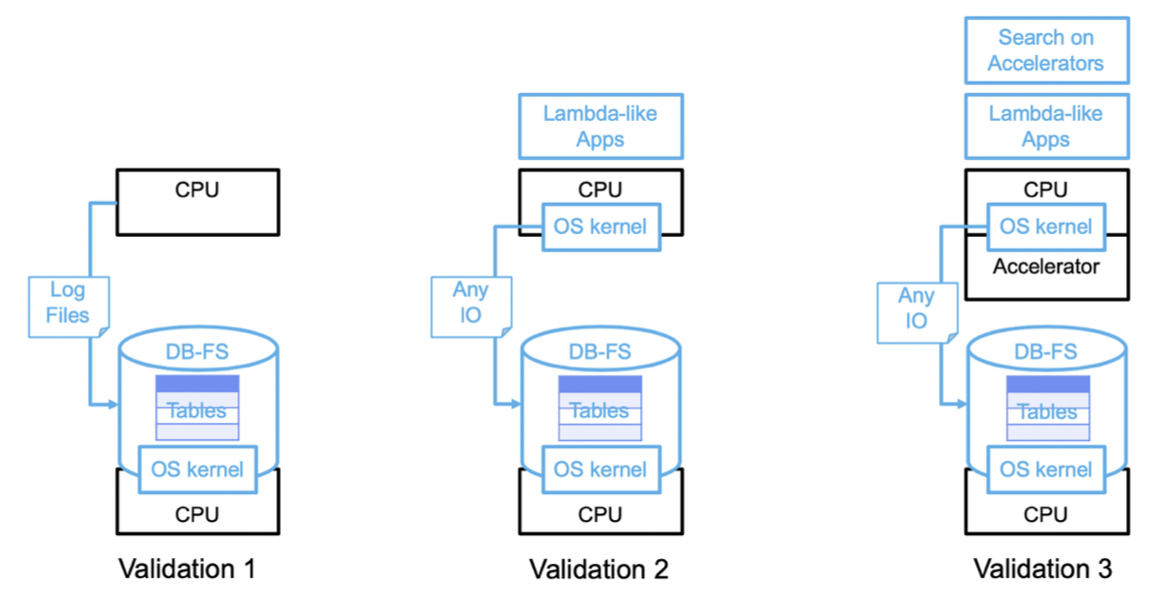
DBOS: A proposal for a data-centric operating system
The International Journal on Very Large Data Bases (VLDB), 2020
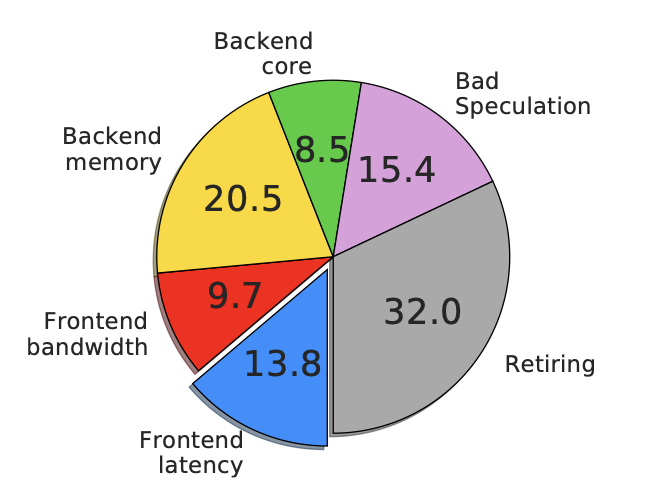
Asmdb: Understanding and mitigating front-end stalls in warehouse-scale computers
International Symposium on Computer Architecture (ISCA), 2020
Interstellar: Using Halides Scheduling Language to Analyze DNN Accelerators
ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2020
Classifying memory access patterns for prefetching
ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2020
From laptop to lambda: outsourcing everyday jobs to thousands of transient functional containers
USENIX Annual Technical Conference (USENIX ATC), 2020
2019
Mind the gap: A case for informed request scheduling at the nic
ACM Workshop on Hot Topics in Networks (HotNets), 2019
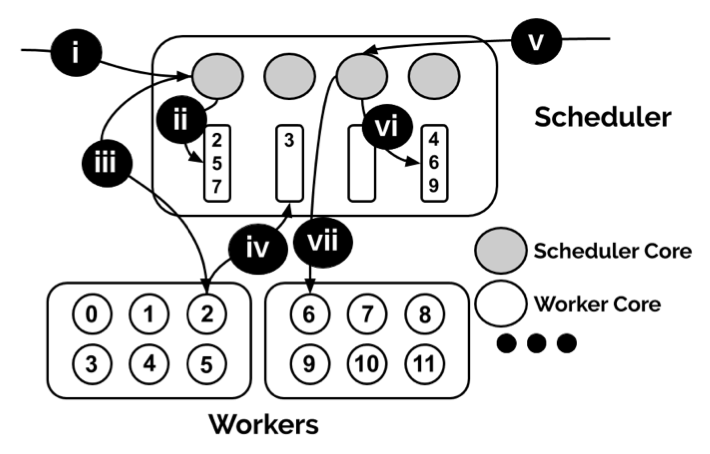
Centralized core-granular scheduling for serverless functions
ACM Symposium on Cloud Computing (SoCC), 2019

INFaaS: A model-less and managed inference serving system
USENIX Annual Technical Conference (USENIX ATC), 2019
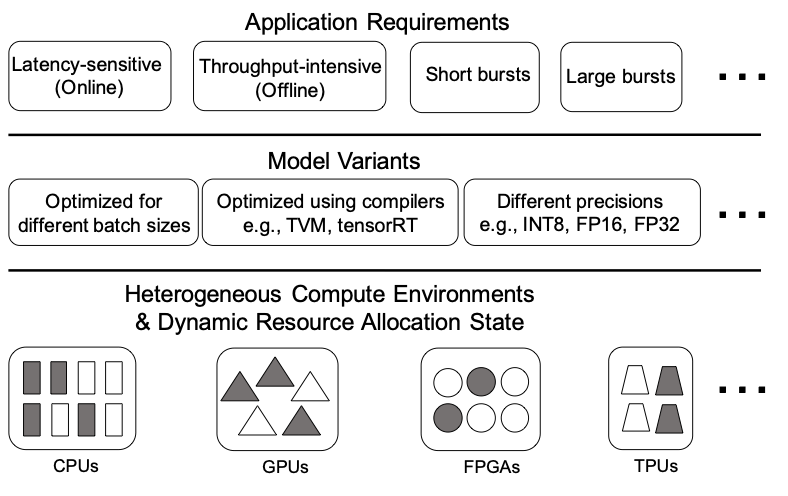
A case for managed and model-less inference serving
USENIX Workshop on Hot Topics in Operating Systems (HotOS), 2019
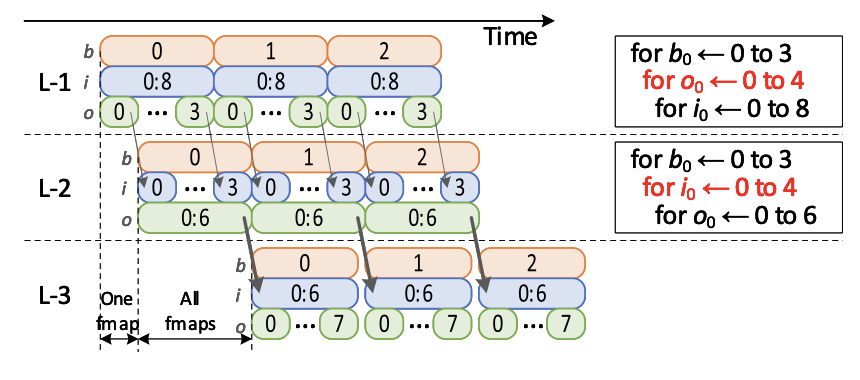
Tangram: Optimized coarse-grained dataflow for scalable nn accelerators
ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2019
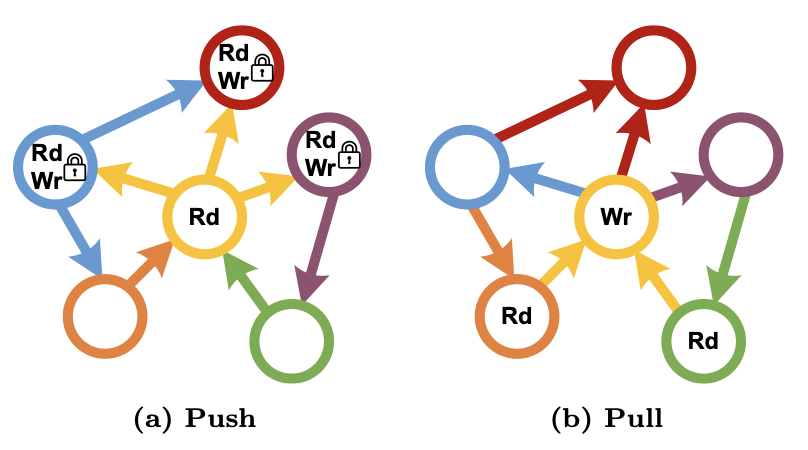
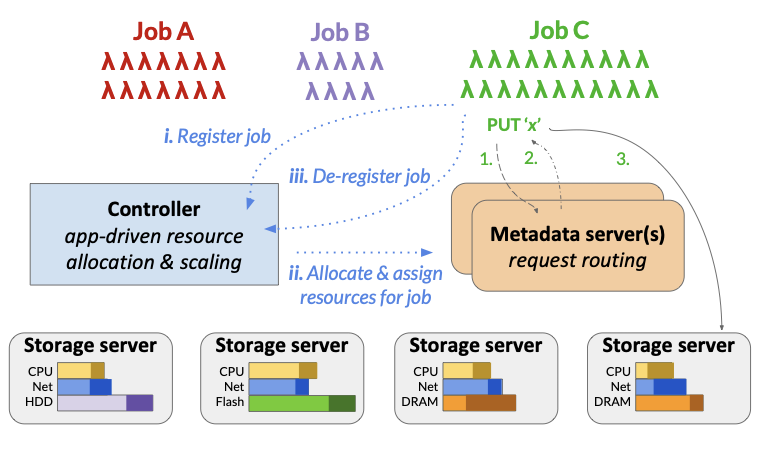
Pocket: Elastic Ephemeral Storage for Serverless Analytics
USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2019
2018
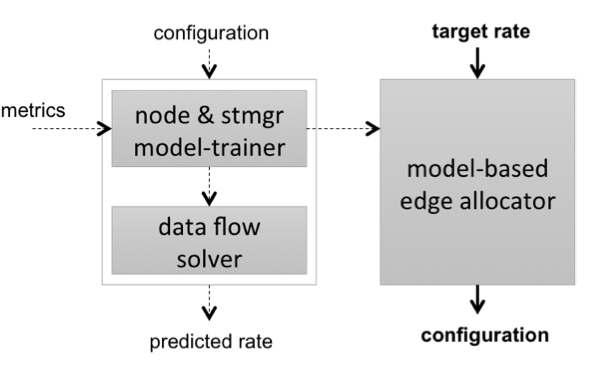
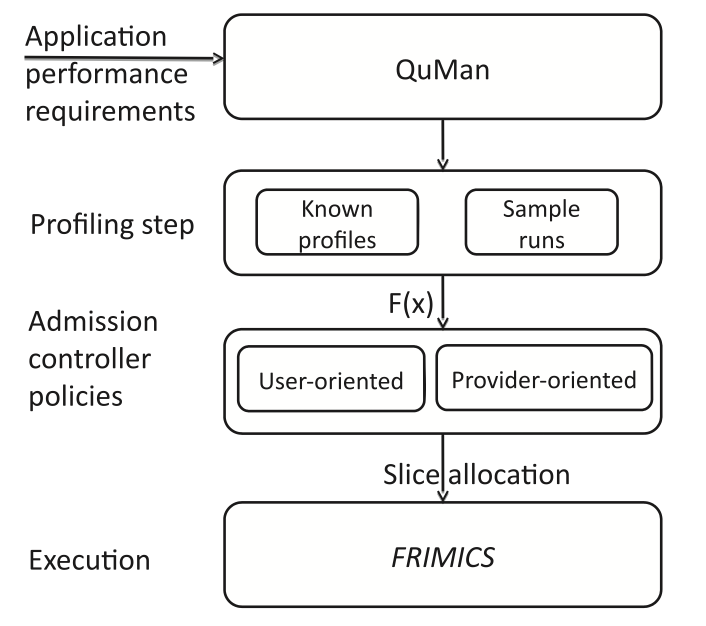
QuMan Profile-based Improvement of Cluster Utilization
ACM Transactions on Architecture and Code Optimization (TACO), 2018
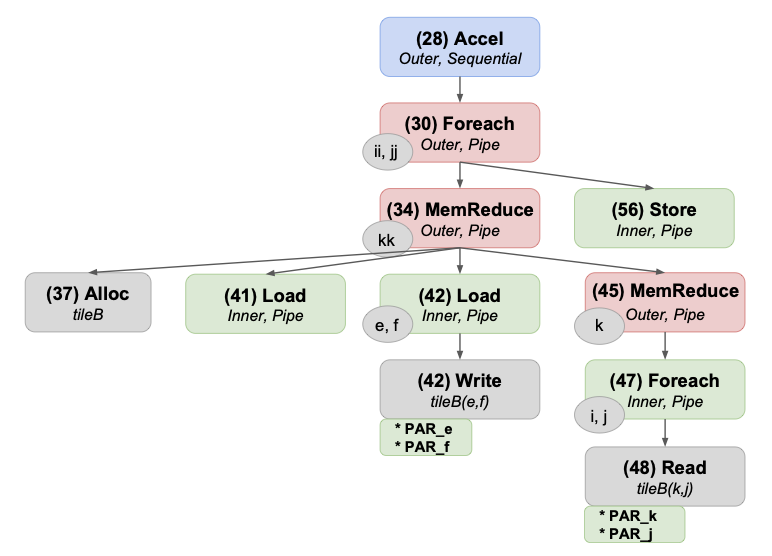
Spatial: A language and compiler for application accelerators
ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), 2018
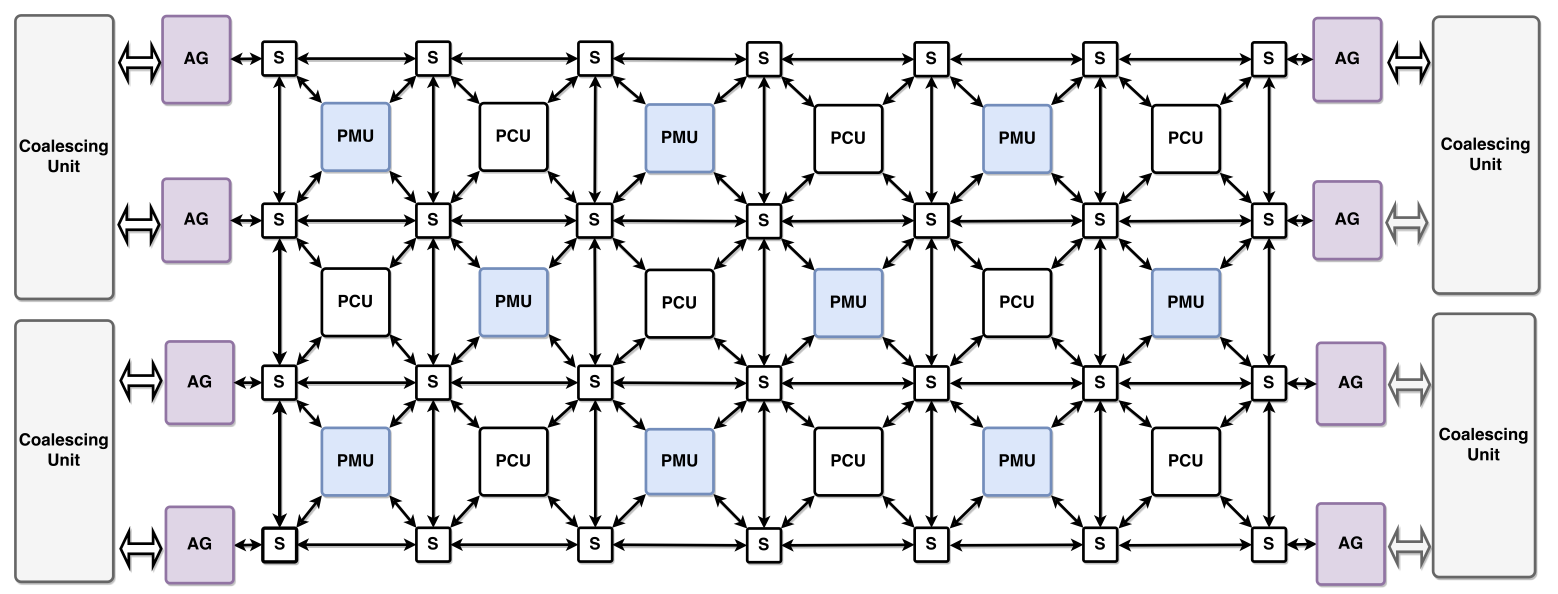
Plasticine: A reconfigurable accelerator for parallel patterns
International Symposium on Computer Architecture (ISCA), 2018
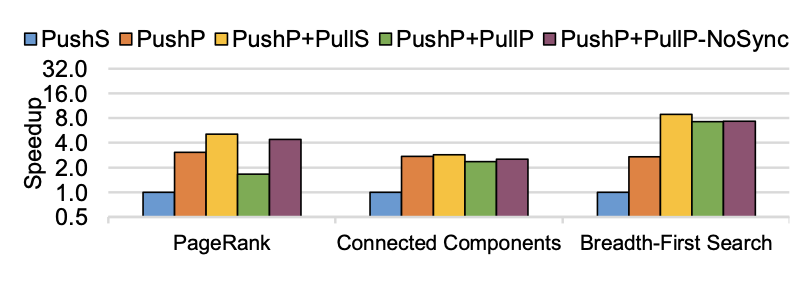
Making pull-based graph processing performant
ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP), 2018
2017
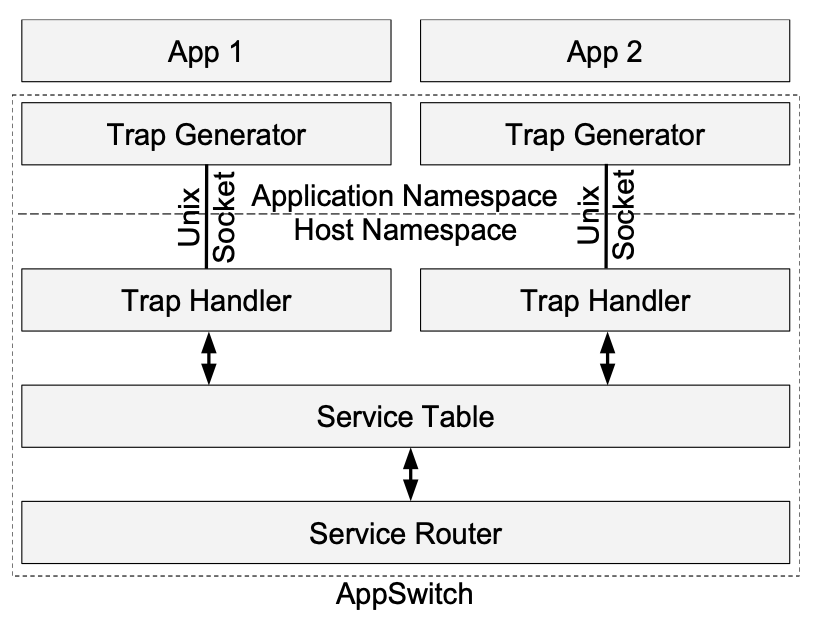
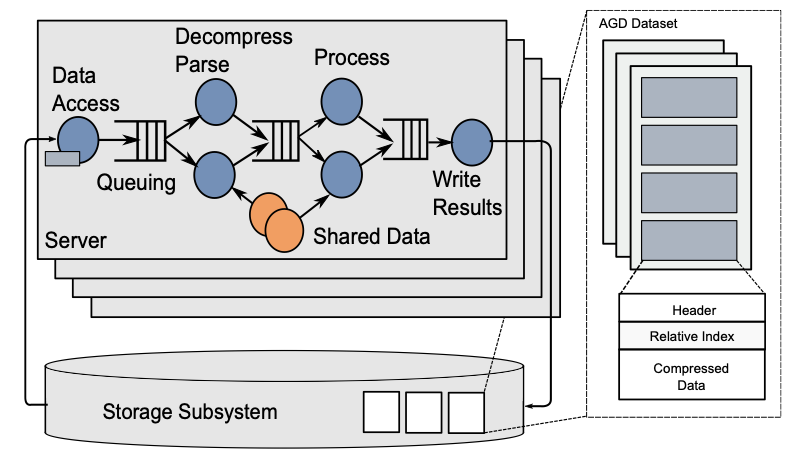
Persona: A High-Performance Bioinformatics Framework
USENIX Annual Technical Conference (USENIX ATC), 2017
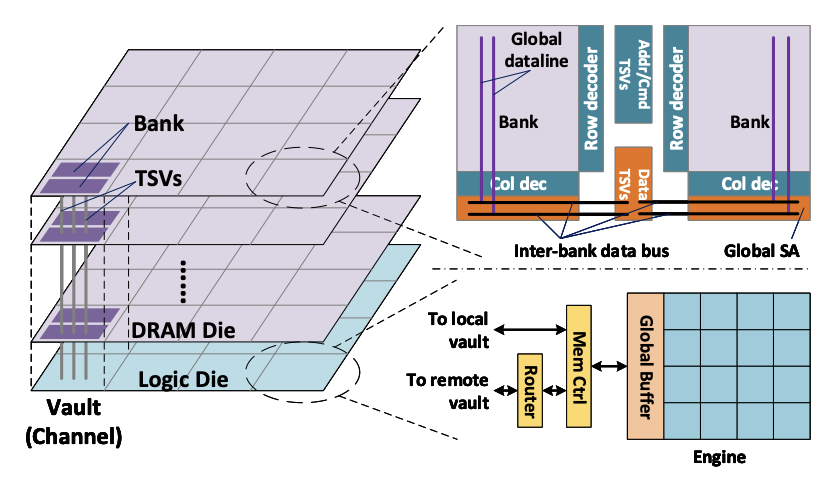
Tetris: Scalable and efficient neural network acceleration with 3d memory
ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2017
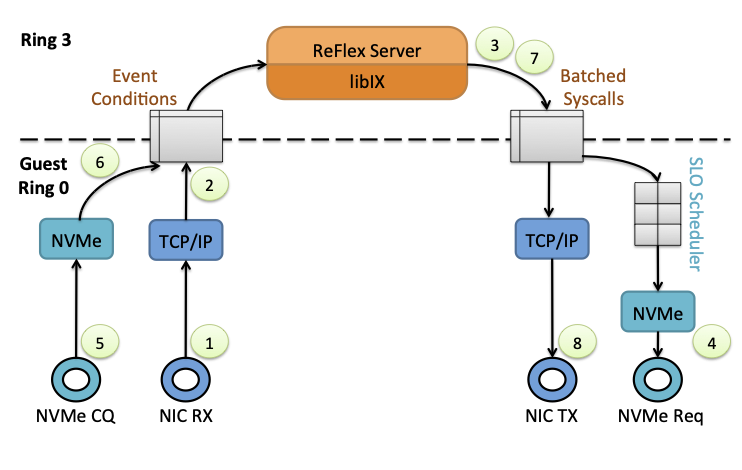
Reflex: Remote flash≈ local flash
ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2017
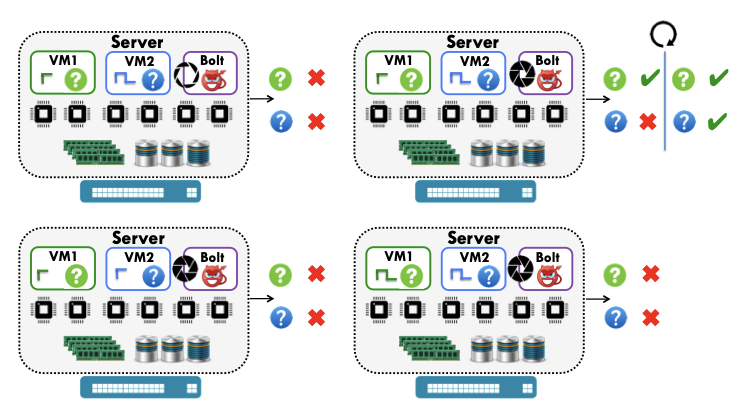
Bolt: I know what you did last summer... in the cloud
ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2017
2016
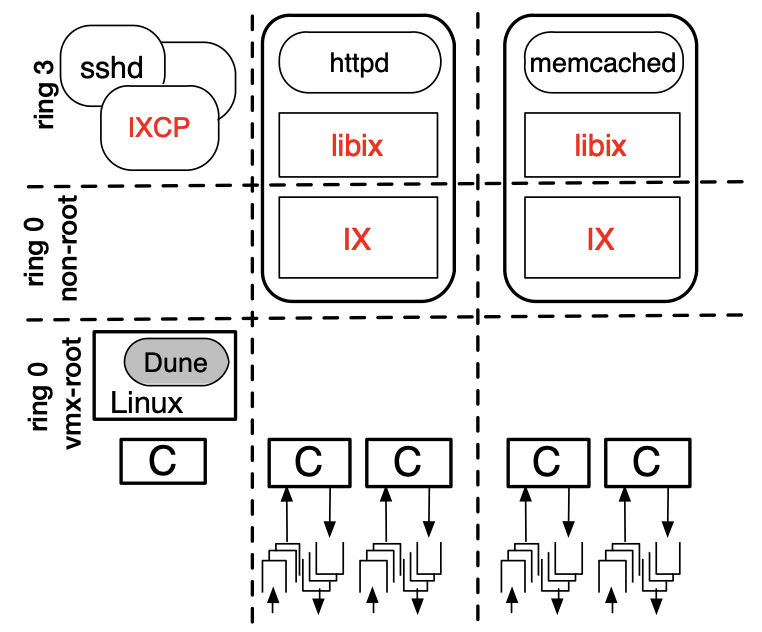
The IX operating system: Combining low latency, high throughput, and efficiency in a protected dataplane
ACM Transactions on Computer Systems (TOCS), 2016
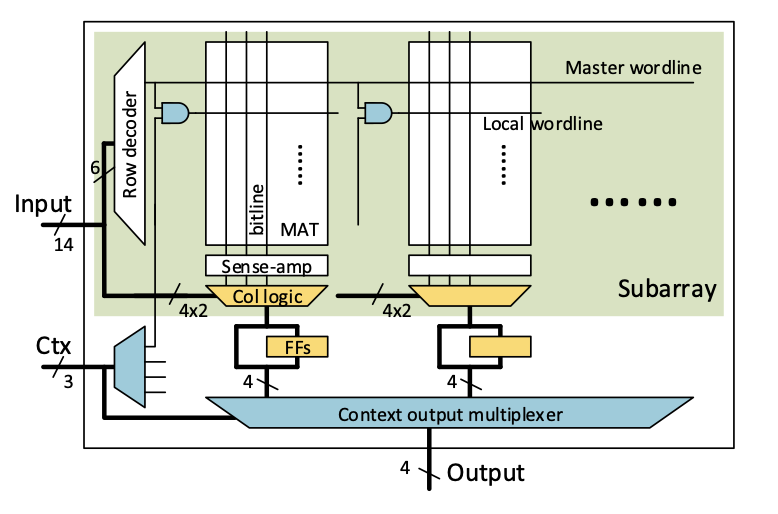
DRAF: A low-power DRAM-based reconfigurable acceleration fabric
International Symposium on Computer Architecture (ISCA), 2016
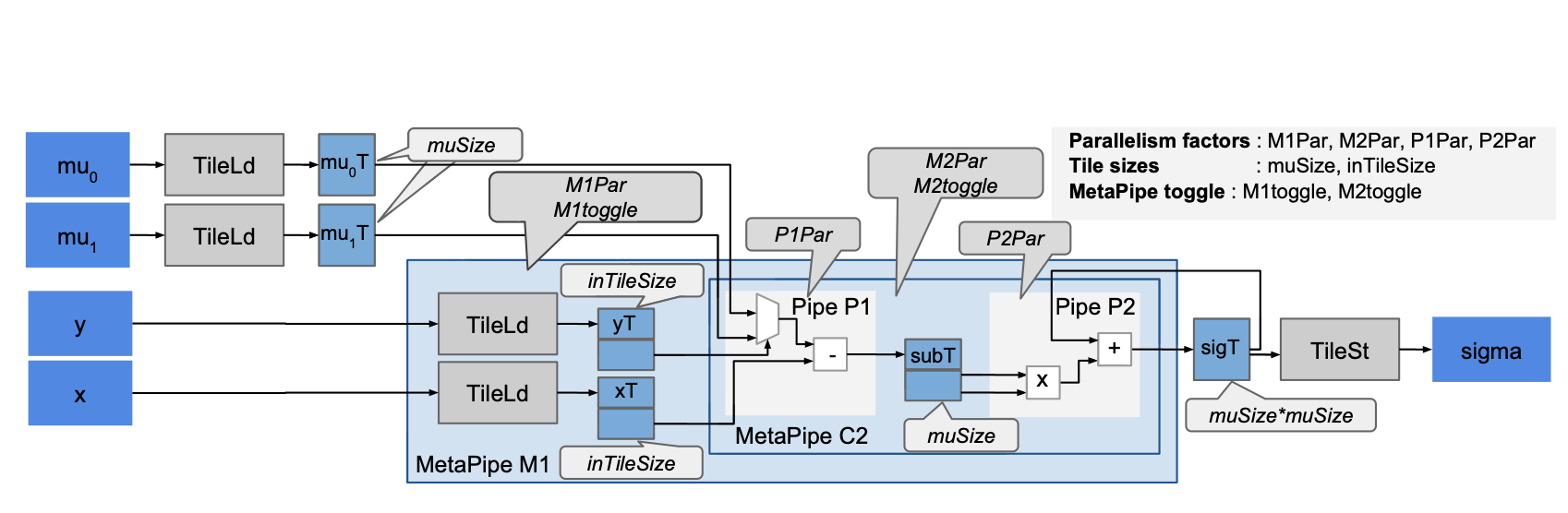
Automatic generation of efficient accelerators for reconfigurable hardware
International Symposium on Computer Architecture (ISCA), 2016
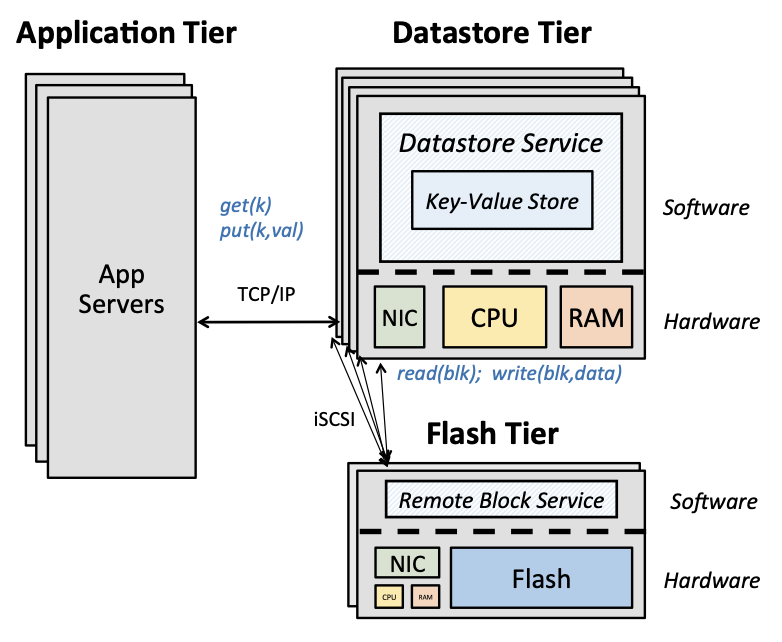
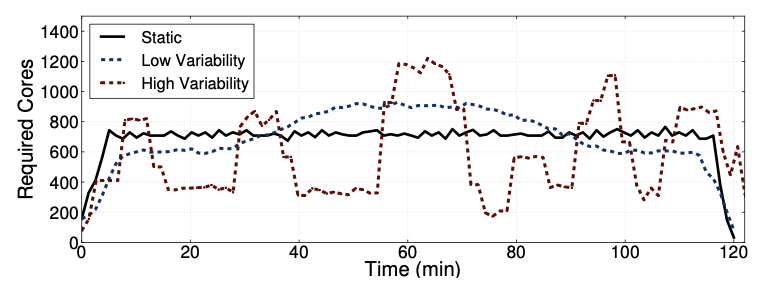
Hcloud: Resource-efficient provisioning in shared cloud systems
ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2016
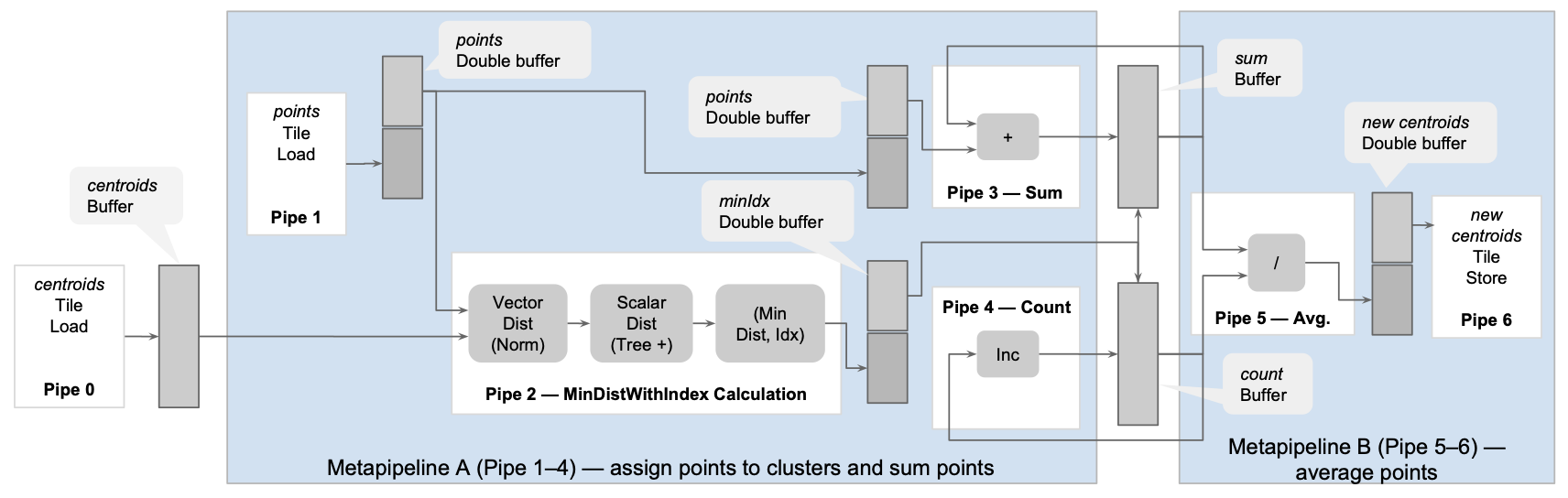
Generating configurable hardware from parallel patterns
ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2016
2015
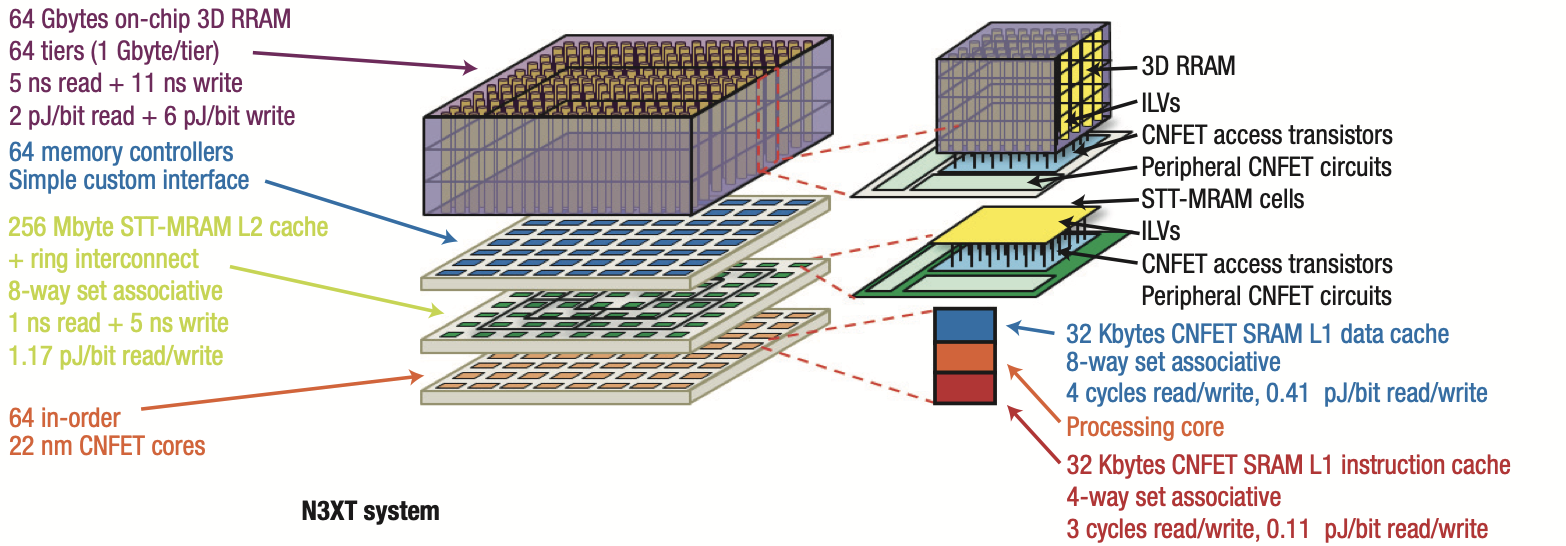
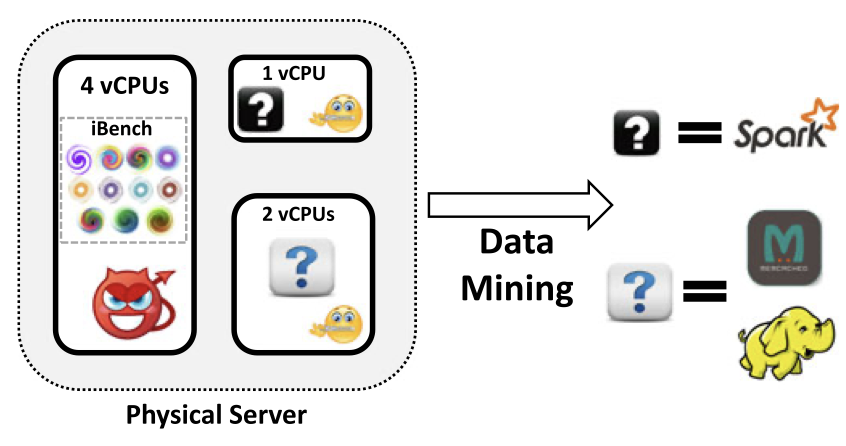
Energy proportionality and workload consolidation for latency-critical applications
ACM Symposium on Cloud Computing (SoCC), 2015
Tarcil: High quality and low latency scheduling in large, shared clusters
ACM Symposium on Cloud Computing (SoCC), 2015
2014
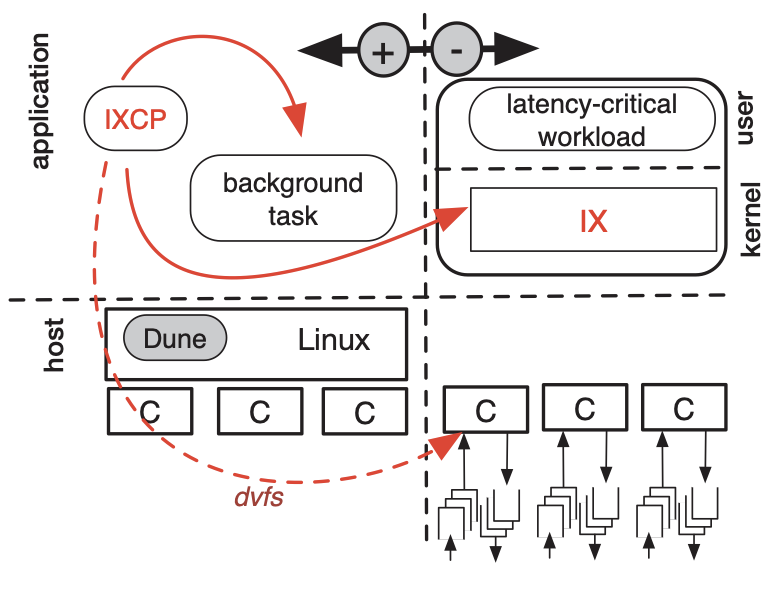
IX: A Protected Dataplane Operating System for High Throughput and Low Latency
USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2014
Towards energy proportionality for large-scale latency-critical workloads
International Symposium on Computer Architecture (ISCA), 2014
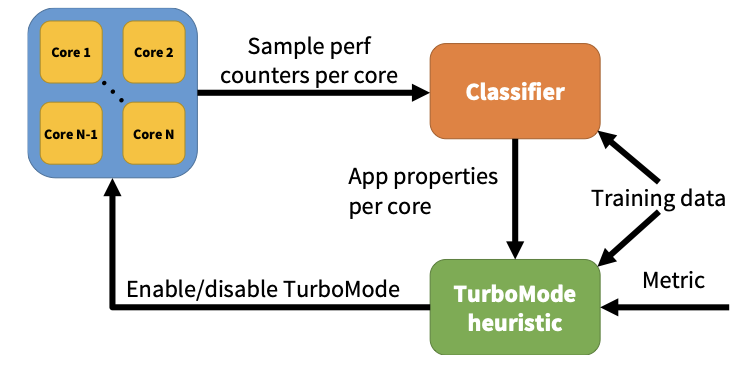
Dynamic management of TurboMode in modern multi-core chips
International Symposium on High-Performance Computer Architecture (HPCA), 2014
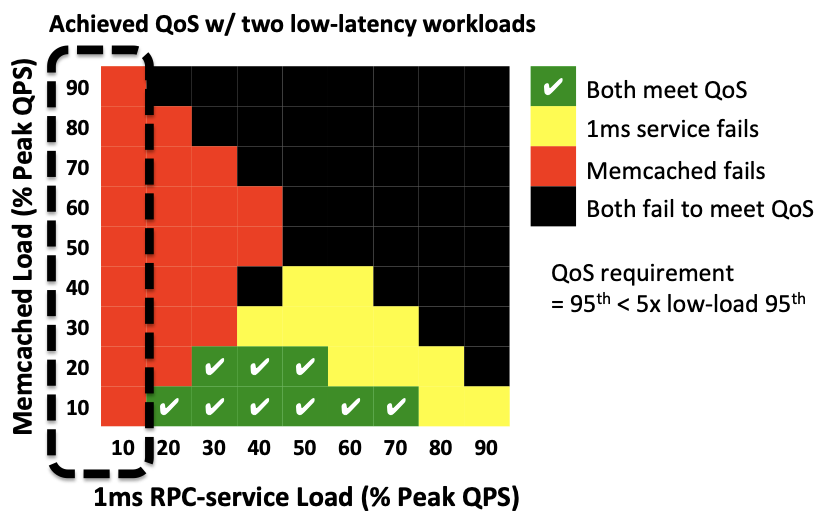
Reconciling high server utilization and sub-millisecond quality-of-service
European Conference on Computer Systems (EuroSys), 2014
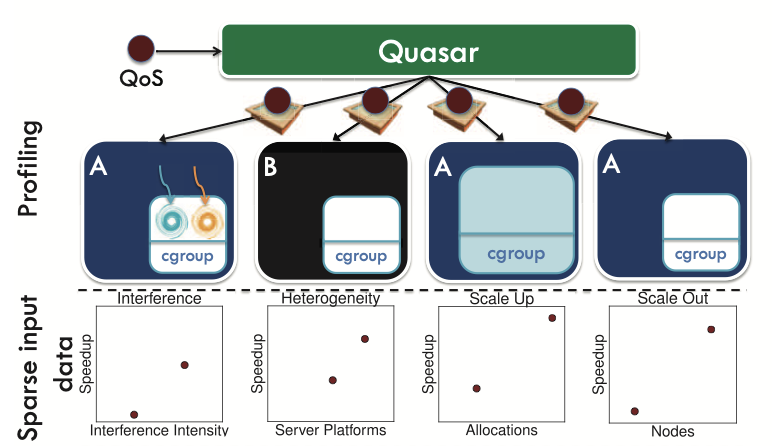
Quasar: Resource-efficient and QoS-aware cluster management
ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2014
2013
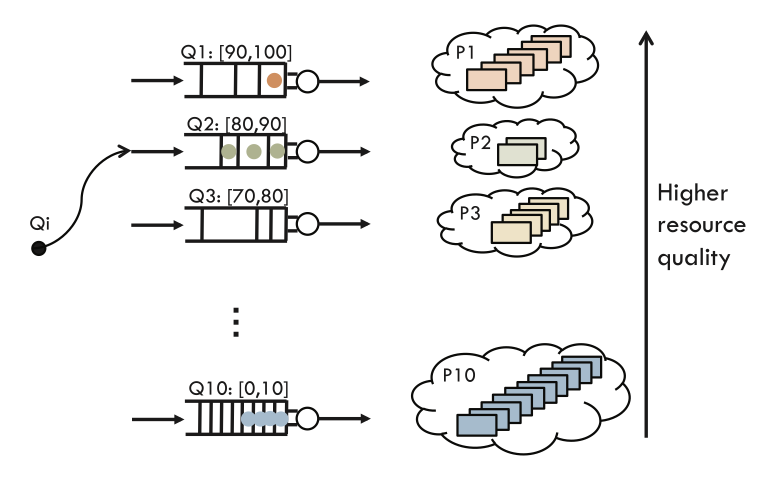
QoS-aware scheduling in heterogeneous data centers with paragon
ACM Transactions on Computer Systems (TOCS), 2013
Measuring and analyzing the energy use of enterprise computing systems
Sustainable Computing Informatics and Systems, 2013
Locality-aware task management for unstructured parallelism: A quantitative limit study
ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), 2013
ZSim: Fast and accurate microarchitectural simulation of thousand-core systems
International Symposium on Computer Architecture (ISCA), 2013
Convolution engine: balancing efficiency & flexibility in specialized computing
Communications of the ACM (CACM), 2013
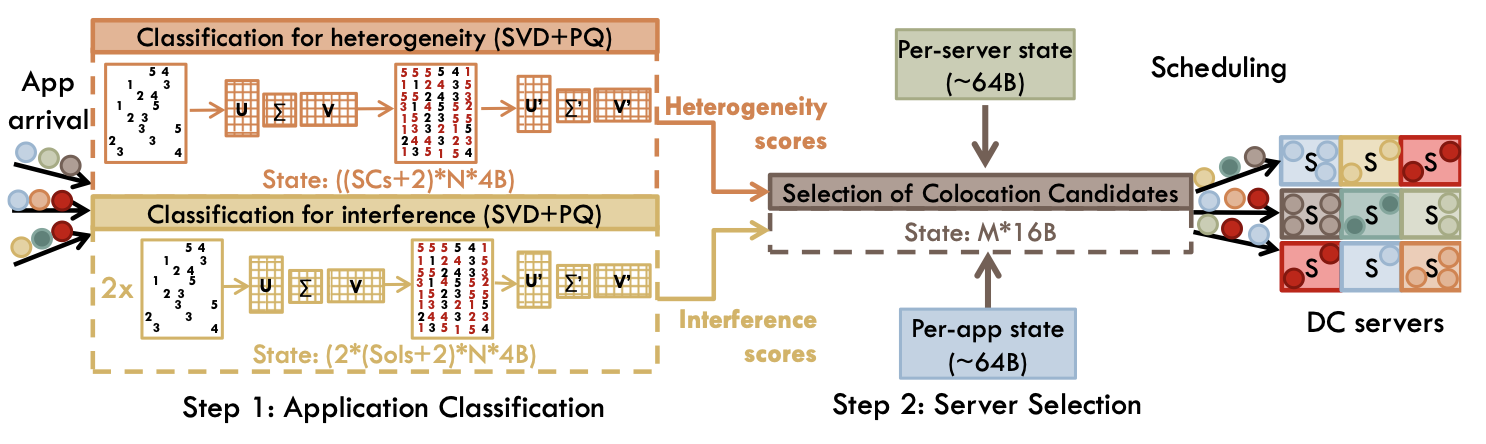
Paragon: QoS-aware scheduling for heterogeneous datacenters
ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2013
2012
A case of system-level hardware/software co-design and co-verification of a commodity multi-processor system with custom hardware
International Conference on Hardware/Software Codesign and System Synthesis (CODES), 2012
Towards energy-proportional datacenter memory with mobile DRAM
International Symposium on Computer Architecture (ISCA), 2012
Green enterprise computing data: Assumptions and realities
International Green Computing Conference (IGCC), 2012
ECHO: Recreating network traffic maps for datacenters with tens of thousands of servers
IEEE International Symposium on Workload Characterization (IISWC), 2012
Dune: Safe User-level Access to Privileged CPU Features
USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2012
Decoupling datacenter studies from access to large-scale applications: A modeling approach for storage workloads
IEEE International Symposium on Workload Characterization (IISWC), 2012
Improving system energy efficiency with memory rank subsetting
ACM Transactions on Architecture and Code Optimization (TACO), 2012
2011
MARS: adaptive remote execution for multi-threaded mobile devices
ACM SOSP Workshop on Networking, Systems, and Applications on Mobile Handhelds (MobiHeld), 2011
Time and cost-efficient modeling and generation of large-scale tpcc/tpce/tpch workloads
TPC Technology conference on Topics in Performance Evaluation, Measurement and Characterization (TPCTC), 2011
Vantage: Scalable and efficient fine-grain cache partitioning
International Symposium on Computer Architecture (ISCA), 2011
Hardware acceleration of transactional memory on commodity systems
ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2011
Accurate modeling and generation of storage i/o for datacenter workloads
ACM Transactions on Storage (ToS), 2011
2010
Understanding sources of inefficiency in general-purpose chips
International Symposium on Computer Architecture (ISCA), 2010
Making nested parallel transactions practical using lightweight hardware support
International Conference on Supercomputing (ICS), 2010
Implementing and evaluating nested parallel transactions in software transactional memory
ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), 2010
An analysis of on-chip interconnection networks for large-scale chip multiprocessors
ACM Transactions on Architecture and Code Optimization (TACO), 2010
Flexible architectural support for fine-grain scheduling
ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2010
2009
Future scaling of processor-memory interfaces
International Conference for High Performance Computing, Networking, Storage and Analysis (SC), 2009
Power management of datacenter workloads using per-core power gating
IEEE Computer Architecture Letters, 2009
Optimizing memory transactions for multicore systems
Multicore Processors and Systems. Integrated Circuits and Systems, 2009
Fast memory snapshot for concurrent programmingwithout synchronization
International Conference on Supercomputing (ICS), 2009
A memory system design framework: creating smart memories
International Symposium on Computer Architecture (ISCA), 2009
2008
Hardware Enforcement of Application Security Policies Using Tagged Memory.
USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2008
Comparative evaluation of memory models for chip multiprocessors
ACM Transactions on Architecture and Code Optimization (TACO), 2008
A comparison of high-level full-system power models.
USENIX Workshop on Hot Topics in Power Aware Computing (HotPower), 2008
Improving software concurrency with hardware-assisted memory snapshot
ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), 2008
Ased: availability, security, and debugging support usingtransactional memory
ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), 2008
2007
A low power front-end for embedded processors using a block-aware instruction set
International Conference on Compilers, Architecture, and Synthesis for Embedded Systems (CASES), 2007
Towards soft optimization techniques for parallel cognitive applications
ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), 2007
Raksha: a flexible information flow architecture for software security
International Symposium on Computer Architecture (ISCA), 2007
JouleSort: a balanced energy-efficiency benchmark
ACM International Conference on Management of Data (SIGMOD), 2007
Comparing memory systems for chip multiprocessors
International Symposium on Computer Architecture (ISCA), 2007
An effective hybrid transactional memory system with strong isolation guarantees
International Symposium on Computer Architecture (ISCA), 2007
Transactional programming in a multi-core environment
ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP), 2007
Transactional collection classes
ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP), 2007
From chaos to QoS: case studies in CMP resource management
ACM SIGARCH Computer Architecture News, 2007
A Practical FPGA-based Framework for Novel CMP
ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA), 2007
2006
Tradeoffs in transactional memory virtualization
ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2006
Testing implementations of transactional memory
International Conference on Parallel Architectures and Compilation Techniques (PACT), 2006
Block-aware instruction set architecture
ACM Transactions on Architecture and Code Optimization (TACO), 2006
The Atomos transactional programming language
ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), 2006
Parallelizing specjbb2000 with transactional memory
Workshop on Transactional Memory Workloads (WTW) at PLDI, 2006
Deconstructing hardware architectures for security
Annual Workshop on Duplicating, Deconstructing, and Debunking, 2006
Architectural semantics for practical transactional memory
International Symposium on Computer Architecture (ISCA), 2006
Building and using the atlas transactional memory system
Workshop on Architecture Research with FPGAs (WARP), 2006
2005
Improving instruction delivery with a block-aware ISA
European Conference on Parallel Processing (Euro-Par), 2005
Energy-efficient and high-performance instruction fetch using a block-aware ISA
International Symposium on Low Power Electronics and Design (ISPLD), 2005
TAPE: A transactional application profiling environment
International Conference on Supercomputing (ICS), 2005
ATLAS: A Scalable Emulator for Transactional Parallel Systems
Workshop on Architecture Research with FPGAs (WARP), 2005
2004
Programming with transactional coherence and consistency (TCC)
ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2004
Viram1: A media-oriented vector processor with embedded dram
Design Automation Student Design Contest, 2004
Transactional memory coherence and consistency
International Symposium on Computer Architecture (ISCA), 2004